
Fri Jul 27 2018
Scaling webapps for newbs & non-techies
 This guide summarizes the basic principles of scaling - from a single server to a web app capable of serving millions of users. It is aimed at newcomers and non-developers working in technical fields - so if you've just deployed your multi-cloud-terraform-vpn-setup, this one is not for you.
This guide summarizes the basic principles of scaling - from a single server to a web app capable of serving millions of users. It is aimed at newcomers and non-developers working in technical fields - so if you've just deployed your multi-cloud-terraform-vpn-setup, this one is not for you.
For everyone else though: Let's get started!
Scaling...wut?!?
You've just finished building your website, online store, social network or whatever else it is you are up to, put it online and things are going splendidly: A few hundred visitors pass by your site every day, requests are answered quickly, orders are processed immediately and everything is humming along nicely.
But then something terrible happens: You become successful!
More and more users are flooding in, thousands, tens of thousands, every hour, minute, second... What's fantastic news for your business is bad news for your infrastructure; because now, it needs to scale. That means it needs to be able to:
- serve more costumers simultaneously
- be always available without downtimes
- serve users around the globe
How scaling works
A few years ago, this post would have started with a discussion of "vertical" vs "horizontal" scaling (also called scaling up vs scaling out). In a nutshell, vertical scaling means running the same thing on a more powerful computer whereas horizontal scaling means running many processes in parallel.
Today, almost no one is scaling up / vertically anymore. The reasons are simple:
- computers get exponentially more expensive the more powerful they are
- a single computer can only be so fast, putting a hard limit on how far one can scale vertically
- multi-core CPUs mean that even a single computer is effectively parallel- so why not parallelize from the start?
Alright, horizontal scaling it is! But what are the required steps?
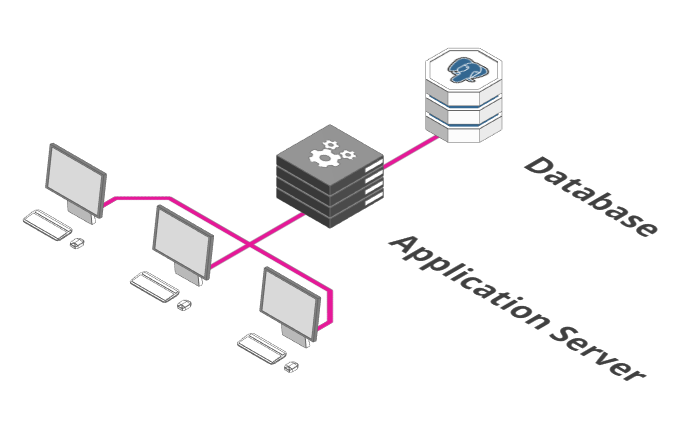
1. A single server + database
2. Adding a Reverse Proxy
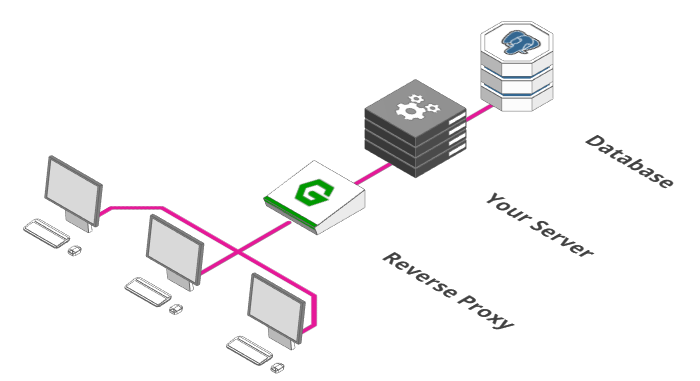
Such a proxy fulfills a number of tasks:
- Health Checks make sure that our actual server is still up and running
- Routing forwards a request to the right endpoint
- Authentication makes sure that a user is actually permissioned to access the server
- Firewalling ensure that users only have access to the parts of our network they are allowed to use ... and more
3. Introducing a Load Balancer
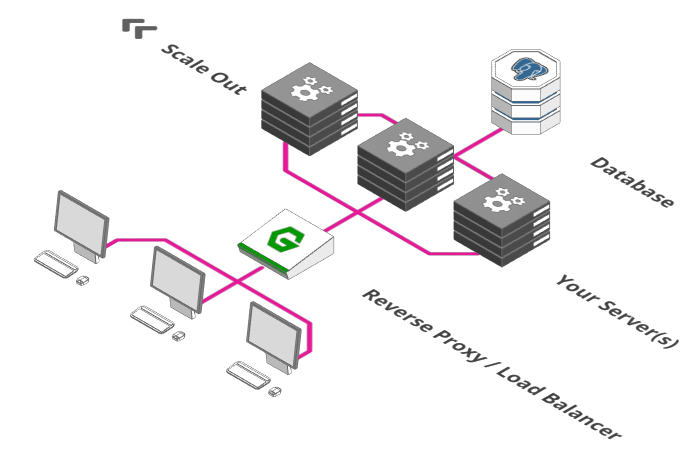
A load balancer's job is now to split incoming payment requests between these two servers. User one goes left, user two goes right, user three goes left and so on.
And what do you do if five-hundred users want to pay at once? Exactly, you scale to ten payment servers and leave it to the load balancer to distribute the incoming requests between them.
4. Growing your Database
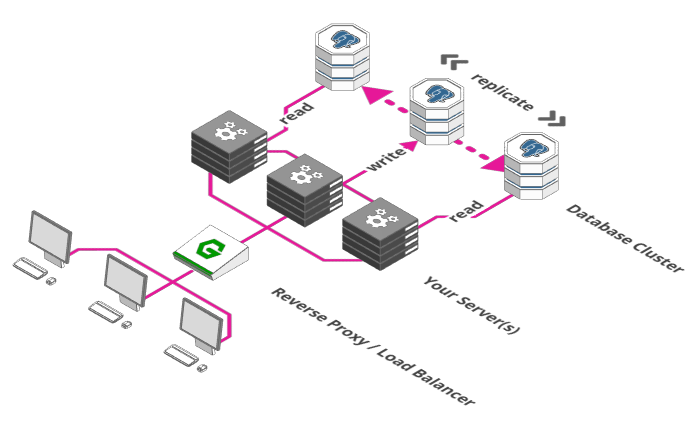
So can't we just scale the database the same way? Unfortunately not. The problem here is consistency. All parts of our system need to agree on the data they are using. Inconsistent data leads to all sorts of hairy problems - orders being executed multiple times, two payments of $90 being deducted from an account holding $100 and so on... so how do we grow our database while ensuring consistency?
The first thing we can do is split it into multiple parts. One part is exclusively responsible for receiving data and storing it, all other parts are responsible for retrieving the stored data. This solution is sometimes called a Master/Slave setup or Write with Read-replicas. The assumption is that servers read from the database way more often than they write to it. The good thing about this solution is that consistency is guaranteed since data is only ever written to a single instance and flows from there in one direction, from write to read. The downside is that we still only have a single database instance to write to. That's ok for small to medium web projects, but if you run Facebook it won't do. We'll look into further steps to scale our DB in chapter 9.
5. Microservices
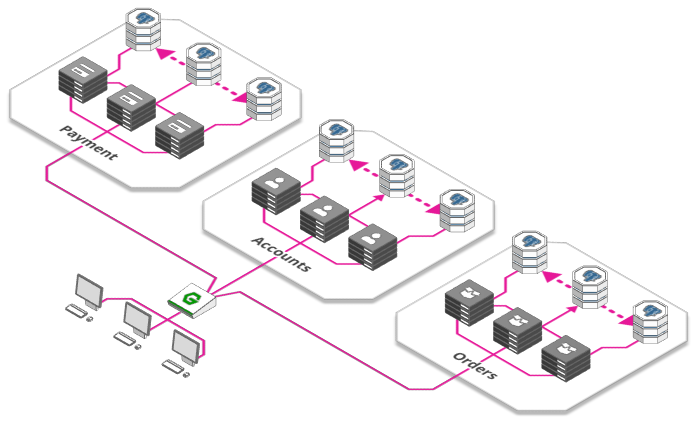
That's not necessarily a bad thing - a single server means lower complexity and thus less headache for our developers. But as scale increases, things start getting complicated and inefficient:
- different parts of our server are utilized to different extents - for every user login there's probably a few hundred pageviews to handle and assets to serve, yet all is done by the same server
- our development team grows with our app - but as more developers work on the same server they are more likely to step on each other's toes.
- Having only a single server means that everything has to be done and dusted whenever we want to take a new version live. This results in dangerous interdependencies whenever one team quickly wants to release an update, but another team is only half done with their work.
The solution to these challenges is an architectural paradigm that has taken the dev world by storm: Microservices. The idea is simple - break your server down into functional units and deploy them as individual, interconnected mini-servers. This has a number of benefits:
- each service can be scaled individually, enabling us to better adjust to demand
- development teams can work independently, each being responsible for their own microservice's lifecycle (creation, deployment, updating etc.)
- each microservice can use its own resources, e.g. its own database further reducing the problem described in 4.)
6. Caching & Content Delivery Networks
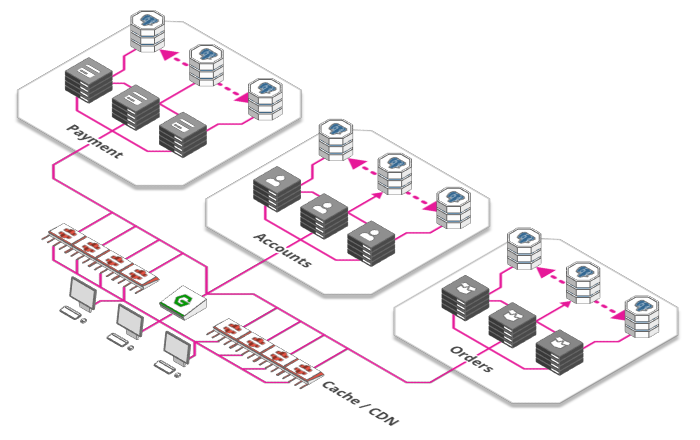
A cache's bigger brother is called a "Content Delivery Network" or CDN for short - a huge array of caches placed all around the world. This allows us to serve content to our users from a store physically close to them, rather than shipping our data across the globe every time.
7. Message Queues
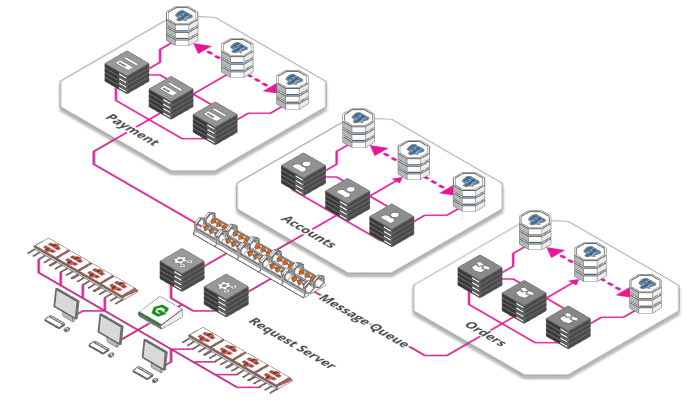
The same concept is used for large web apps. Hundreds of thousands of images are uploaded to Instagram, Facebook and Co every minute, each of which needs to be processed, resized, analyzed and tagged - a time-consuming process. So rather than making the user wait until their upload has gone through all these steps. the server receiving the image only does three things:
- it stores the raw, unprocessed image
- it confirms the upload to the user
- it adds a virtual sticky-note to a large pile, specifying what needs to be done
From here on this note is picked up by any number of other servers, each fulfilling one of its tasks, ticking it off and putting the note back onto the pile - until our todo list is complete. The system managing this pile of notes is called a "message queue". Using such a queue has a number of advantages:
- it decouples tasks and processors. Sometimes a lot of images need to be processed, sometimes only a few. Sometimes a lot of processors are available, sometimes its just a couple. By simply adding tasks to a backlog rather than processing them directly we ensure that our system stays responsive and no tasks get lost.
- it allows us to scale on demand. Starting up more processors takes time - so by the time a lot of users tries to upload images, it's already too late. By adding our tasks to a queue we can defer the need to provision additional capacities to process them
Alright, if we followed all the steps above our system is now ready to serve a sizable amount of traffic. But what can we do if we want to go big - really big? Well, there are still a few options left:
8. Sharding, Sharding, Sharding
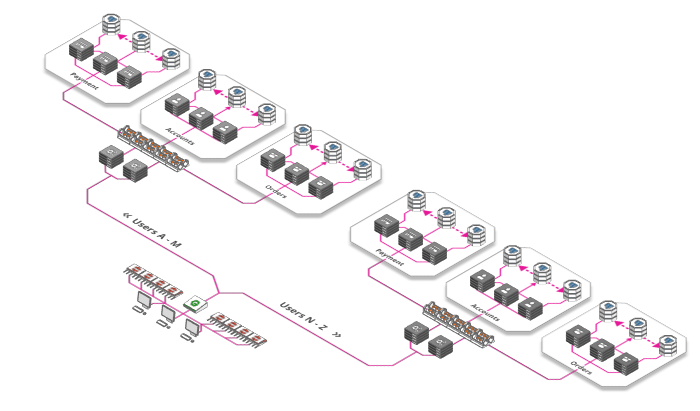
"Sharding is a technique of parallelizing an application's stacks by separating them into multiple units, each responsible for a certain key or namespace"
...phew. So what exactly does that mean? It's actually quite simple: Need to serve Facebook profiles for 2 billion users? Break your architecture down into e.g. 26 Mini-Facebooks, each serving users with a different letter of the alphabet. Aaron Abrahams? You'll be served by stack A. Zacharias Zuckerberg? Stack Z it is...
Sharding doesn't have to be based on letters but can be based on any number of factors, e.g. location, usage frequency (power-users are routed to the good hardware) and so on. You can shard servers, databases or almost any aspect of your stack this way, depending on your needs.
9. Load-balancing the load-balancer
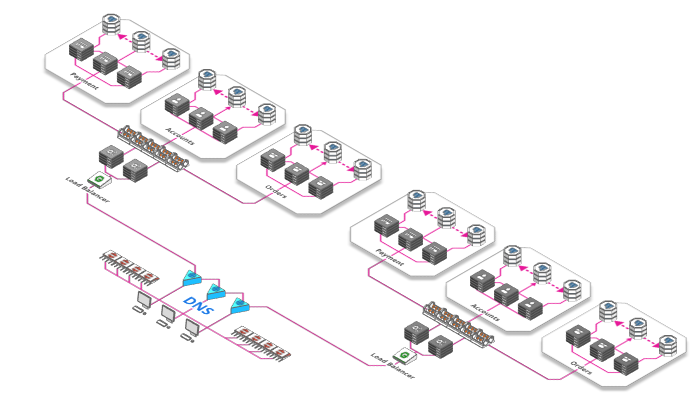
Fortunately, there is a worldwide, decentralized and incredibly stable layer that can be used to load-balance traffic even before it hits our load balancers. And the best thing? It's absolutely free. This layer is the "Domain Name System" - or DNS for short. The worldwide registry mapping domain names such as "arcentry.com" to IPs such as "143.204.47.77". This registry allows us to specify multiple IPs per domain name, each leading to a different load balancer.
Phew, this was a lot to take in. Thanks for holding out with me for so long. I hope there was something useful in this blog post for you. But - if you are working in any IT related field there was probably one question burning on your chest throughout reading this text: "What about cloud services?"
Cloud Computing / Serverless
But what about cloud services? Well - it is 2018 and the cheapest and most efficient solution to a lot of the problems described above is pretty clear:
Don't solve them at all.
Instead, leave it to your cloud provider to give you a system that simply scales to your demands without you having to worry about its intricacies.
Arcentry, for instance, doesn't do any of the things described above (apart from the write/read split for its DB), but simply leaves it to Amazon Web Service's Lambda functions to run its logic - no servers, no hassle.
But the cloud isn't something you simply turn on and all your problems are solved - it comes with its own set of challenges and trade-offs. Stay tuned for the next article in this series to learn more about "the cloud for newbs and non-techies"