
Thu Nov 08 2018
Four predictions for the next decade of Cloud Computing
The cloud's key promise of "less infrastructure, more business value" - holds as true as ever. But the way the cloud delivers on this promise - and the way that users adopt it - is undergoing significant change.
It is, of course, always hard to make predictions about something as young and dynamic as cloud infrastructure, but I believe there are four distinct trends that are likely to accelerate over the next decade and that are already fundamentally reshaping what "the cloud" really is:
1) Ever higher level offerings
 From home-servers to rented hardware to virtual hosts to VMs to Containers to Serverless - few trends in the tech world are as clear-cut as the move towards ever higher level offerings, hiding increasingly larger parts of their underlying infrastructure.
From home-servers to rented hardware to virtual hosts to VMs to Containers to Serverless - few trends in the tech world are as clear-cut as the move towards ever higher level offerings, hiding increasingly larger parts of their underlying infrastructure.
This is a positive development for cloud service providers and their users alike - as it enables the former to use their resources more efficiently and the later to worry less about the infrastructure that runs their code. But in order to become the standard way of using the cloud, fully managed offerings still have to work out how to truly scale.
Catering to Facebook's 2.27 billion users or providing Netflix' 15% of global internet traffic requires a lot of bespoke solutions on both a hard- and software level. Usually, these focus on breaking a large problem down into many smaller chunks, employing clever sharding, distribution and replication strategies and tailoring resource usage to the exact requirements of one's platform.
This is fundamentally at odds with the premise of a fully managed cloud. The value proposition of Functions-as-a-Service offerings such as AWS Lambda or Google Cloud Functions is that "code just runs in response to incoming traffic" - without users having to worry about scale. The same is even more relevant for managed databases such as Azure's CosmosDB or AWS DynamoDB that must offer strong consistency: the guarantee that data is exactly the same at the time of retrieval, regardless of its location around the globe.
To overcome these challenges we will need to find a new generation of solutions. Intelligent distribution and pre-loading of code for FaaS offerings, AI-driven traffic spike anticipation or systems such as Google's True Time that guarantee scalable consistency by precisely syncing atomic clocks are paving the way.
And who knows - there is still some hope that we'll be able to utilize quantum teleportation for zero-latency transmission of information and state, ushering in a whole new generation of distributed system designs.
2) More diverse environments interconnect
From smartphones to traffic lights to server farms - we're surrounded by ever more powerful computers.
Unfortunately, we're terribly inefficient at using them.
A lot has been written about computational power being the oil of the 21st century - and rightfully so. Yet I would guess that at any given point we're using less than ten percent of the entire computational resources on our planet. Fortunately, we're increasingly waking up to that fact - and started processing on a wider array of devices inside and outside of the cloud (an approach referred to as edge or fog computing, although there is still some ambiguity about what that exactly means).
We're also connecting more things to the internet and we are getting more accustomed to integrating everything from our globally distributed production chain to our banking and finance operations to the cloud.
And last but not least the cloud itself is becoming a more diverse place. We've long been linking our local on-premise infrastructure to cloud resources - but we're also increasingly venturing into multi-cloud deployments and see a rise in smaller, specialized cloud vendors that either limit themselves to a specific API or functionality (e.g. email, payment, machine learning, conversational UI/NLP etc.) or a specific sector such as banking, healthcare or automotive.
Yet to truly interconnect and utilize the computational resources at our disposal we still have to overcome two major obstacles:
we need to make computational resources more discoverable and accessible. Projects such as Ethereum for distributed computation or IPFS for distributed storage are promising beginnings, but we're still far from a highly efficient "sharing economy of computation"
we need to converge on a more widely accepted set of standards that allow us to turn inter-cloud communication from a substantial integration exercise into a simple plug-and-play affair.
While the WWW itself has arguably reached a state of consolidation with its central protocol stack of Ethernet -> IP -> TCP -> HTTP universally spoken and understood, the layer above HTTP is still widely in flux. Earlier API standards like SOAP, WSCL or XML-RPC have been mostly discarded, newer approaches such as GraphQL, gRPC or Falcor have yet to produce a definite standard. The same is true for inter-cloud data-exchange which still very much feels like the Betamax/Laserdisk age of the current era.
3) Auto-orchestration replaces configuration
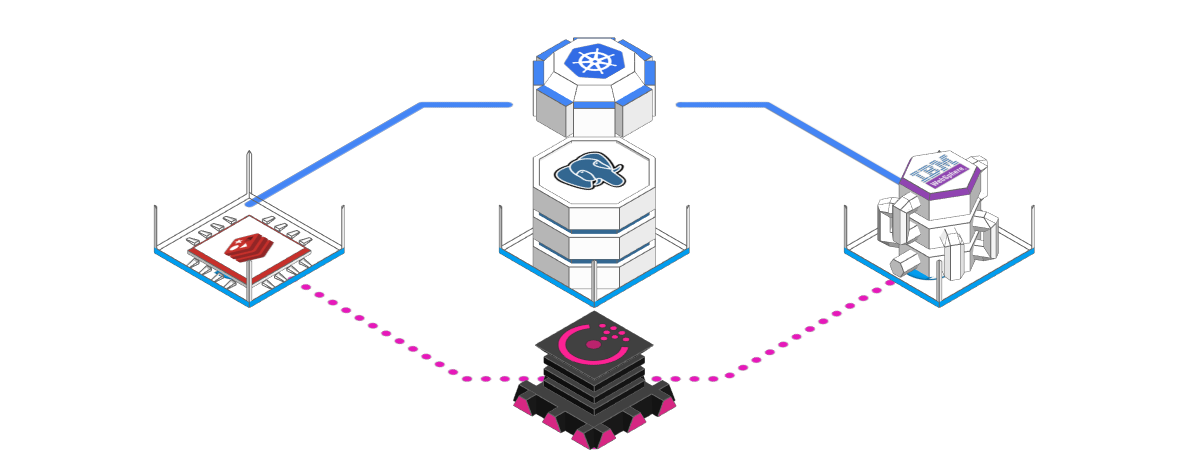
I still remember my first ever cloud-experience: Launching two virtual machines on a (back then) brand new AWS service called "Elastic Compute Cloud" or EC2 for short. I connected to both using a terminal, installed the software I needed and wrote an auto-start script.
And that's already where the story ends. These two instances were all I had. If no one was using my service, they were sitting around idly. If traffic spiked, they slowed down or eventually crashed.
Since those days, cloud-providers and the open source community alike have gone through countless iterations of improving this approach. Earlier attempts such as AWS Elastic Beanstalk were eventually superseded by "containerization" - the bundling of software into self-contained commodity units that are easy to deploy and scale.
The introduction of containers set off an avalanche of orchestration and management tool development - which is still very much in progress, moving at a dizzying pace.
Technologies such as Kubernetes may have taken the lead, but there's no shortage of challengers. In general, it's fair to say that the cloud orchestration space is still in its early days and key technologies such as the use of AI for more efficient and predictive orchestration are yet to make an appearance.
4) Communication will be increasingly woven into the network
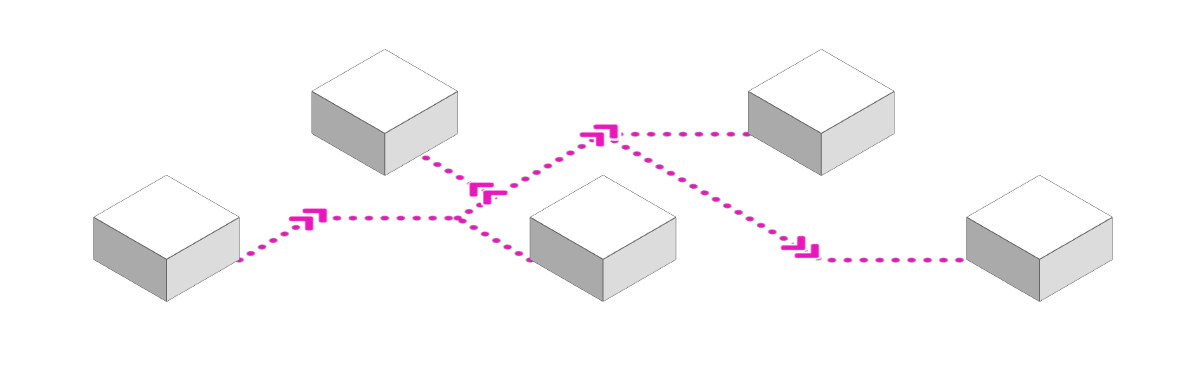
This is certainly the most recent trend on this list - and the one with the hardest to predict trajectory.
In a nutshell, communication within complex networks is increasingly becoming decentralized. In the era of monolithic web servers, messaging could be handled by a centralized bus - but with the growing fragmentation of infrastructure into microservices, inter-service communication through a central hub can quickly become overly complex and a performance bottleneck.
This is aggravated by the challenge of service discovery in dynamic environments: enabling short-lived nodes within a (globally distributed) network to find and talk to each other in the most efficient way is no easy task.
A recent solution is the composition of microservices into service meshes, either by using orchestrations servers such as Hashicorp's Consul or "sidecars" such as Linkerd.
It feels, however, like this is a more fundamental and - with the rise of ever bigger networks consisting of ever smaller services - increasingly important challenge that could be better addressed on a lower level. For the World Wide Web itself, discovery and routing is handled by the globally distributed, yet fairly static domain name system (DNS). It is certainly imaginable that a more dynamic incarnation of DNS, deeply integrated into our networks could be a catalyst for a new era of globally distributed services.
Conclusion
These are just some of the trends that continuously reshape the IT infrastructure landscape - and they are certainly transformative enough on their own.
When we take a step back though and gain a more holistic look, a different picture emerges. The cloud itself (or whatever we'll call the sum of all interconnected computers in the future) is changing into something different - a more organic, dynamic web of ever shape-shifting, deeply interconnected nodes. This leads to exponential gains in efficiency and cost reduction but also challenges us to develop new generations of tools at an ever-accelerating rate to keep up with this fantastic machine we've created.
Where we see ourselves in this development
I hope I'm forgiven for closing with a remark on how these developments relate to the conception of Arcentry (the tool this blog belongs to). With the cloud leap-frogging towards organic structures, current tooling is struggling to keep up. Cloud provider dashboards and monitoring tools in particular are still very much focusing on the individual processes and nodes within a network, thus almost entirely neglecting the bigger picture and struggling to adjust to the increasingly dynamic nature of the cloud.
This leads to a lack of holistic oversight which makes it challenging to find problems in their wider context, use resources efficiently or plan and orchestrate complex infrastructure across the many silos of an organization.
With Arcentry we are aiming to provide a tool that provides a holistic view of a company's infrastructure, honors the dynamic, elastic nature of cloud deployments and provides realtime metrics and structural data in its context - but still respects and facilitates the existing structures and processes of the companies using it. We're only at the very beginning of our journey developing this tool. For a first-hand impression of how we're doing, have a look at our startpage.